Following is the part 1 in a series of posts that aim to provide an analysis and possible solutions for the vulnerable programs provided by
Gera at his
Insecure Programming by example page.
Familiarity with exploit mitigation techniques is expected to gain a proper
understanding of the concepts we talk about here. If terms like ASLR,
NX, SSP, RELRO, etc. seem unfamiliar, I would suggest reading an earlier
post that provides details on these.
We will start with a scenario in which most of the exploit mitigation techniques will be turned on through the default GCC compilation command-line. Since,
these techniques prevent successful exploit attempts, we will incrementally turn
them off until successful exploitation is achieved. This setup will
allow us to witness how these individual techniques succeed in
restricting exploit attempts and how their absence affects exploitation
reliability.
Below is the source for the vulnerable
stack1.c program:
The above program accepts user-input through the gets function and then looks for a specific value in a local variable named cookie. If this value is equal to a certain pre-defined constant, a printf function is used to show a "you win!\n" message to the user. There is no direct means of modifying the content of the cookie variable. The gets function will
keep reading from the stdin device until it encounters a newline or EoF
character. Since this reading loop fails to honor the size of the
destination buffer, a classic buffer overflow vulnerability is
introduced in the program. Our aim is to leverage this vulnerability and
exploit this program so that it print the "you win!\n" message to stdout.
Here are a few observations that could be made by looking at the source of the program:
- Since it is defined prior to buf, the cookie would be placed at a higher memory address on the program stack, just below the saved registers from the function prologue
- The buf character array would be at an offset of at least 80B from cookie
- The gets call would accept unbounded user-input within buf array and hence it provides a mechanism to alter the call stack contents
To attempt exploitation, proper understanding of a program's memory layout and the positioning of its metadata is very important. We first need to understand the
call stack for the
stack1 program.
Whenever a function is called, based upon the
calling convention
in use, metadata information will be pushed on to stack. Upon function
termination this information is popped out of stack. The order in which
variables are pushed and popped is of importance here. On Linux/GCC
environments which use the
cdecl
calling convention, the caller first pushes any function arguments from
right to left in to its stack frame. Then the return address is pushed
and finally the control is transferred to callee's
.text segment. The callee, when initiated, will execute the
function prologue to
set up its stack frame. As a part of prologue, the EBP value is pushed
on to the stack. Since this is the first operation on the stack after
the return address push operation, the EIP and saved EBP end up at
adjacent locations. These two values mark boundary for the caller's and
callee's stack frames. The location of EIP marks the top of caller's
stack frame and the location of saved EBP marks the base of callee's
stack frame.
Refer the below stack layouts for better understanding. The first layout outlines the call stack for the caller
main():
The second layout outlines the call stack for the callee add():
While
control is in the callee function, the passed arguments are accessed by
using EBP as a pointer. According to the calling convention, the first
parameter is located at an offset of EBP+8, the second parameter is
located at an offset of EBP+12, and so on. Using this formula we can
locate function arguments (EBP+8 in the above layout is 32+8 = 40 which stores the first
argument 3 and similarly EBP+12 is 32+12 = 44 which stores the second
argument 6). Since the above described call stack layout will be used for all programs, we could generalize the above formula and use it to find the
offset of EBP itself and then the offset of EIP (EBP+4). The address of EBP is located by summing up the address of the first local variable on the stack with its size. Similarly EIP could be located by adding 4 to the address of the EBP.
Based on these observations, let's try to visualize the call stack layout for the
stack1 program:
NOTE: The stack is assumed to be 4B aligned and we are working on an x86 machine. The addresses in the layouts are for reference only.
While thinking about possible
solutions for this program, I came up with the below listed ideas:
- Solution #1: Overflow the 4B past buf, where the cookie is stored, with the desired value (0x41424344 in this case)
- Solution #2: Overwrite EIP with the address of the printf statement that prints the "you win!\n" message
- Solution #3: Inject and execute a shellcode that simulates the second printf statement, through the internal buf character array
- Solution #4: Inject and execute a shellcode, that simulates the second printf statement, through an environment variable
All right! Let's start with the test execution of this program. Here is a brief description of the test system:
Below is the GCC command-line to compile the stack1.c source file. The -mpreferred-stack-boundary=2 option is used to align stack entries at DWORD (4B) boundary:
GCC outlines a few warnings with the above code, out of which, the last one suggests to find an alternative for the
gets, since it is a "dangerous" function. We are in the process of figuring out just how dangerous
gets can be and hence we can safely ignore this and earlier warnings for now.
Lets have a peak into the assembly code of the
stack1 ELF binary. Below command-line uses the
objdump utility to dump the disassembled object code of a program in
Intel syntax (remove the
-Mintel option from the below command-line to view assembled code in the default AT&T syntax):

There are a few very important points to note from the above output:
- To witness the SSP mitigation technique, locate the mox eax, gs:0x14 instruction at memory address 0x080484aa.
This instruction inserts a random 4B canary value just below the function prologue.
- Variable reordering feature of SSP is also in place since for the initial printf call, the first variable to be pushed on to stack is &cookie instead of &buf (refer cdecl calling convention). This is concluded from the addresses used to move arguments onto stack. The &cookie is accessed from the location [ebp-0x58] and &buf from [ebp-0x54]. As such, cookie is placed at a distance of 88B from EBP and buf is located right above it at a distance of 84B from EBP. The additional 4B are from the canary placed just below EBP.
- The code to verify the content of canary, before returning control to the parent process, is also added and can be found at address 0x080484f0.
If this check fails, the __stack_chk_fail function is called to abort the execution of this program.
NOTE: These SSP feature is enabled by default and
hence it was introduced automatically through the vanilla command-line
we used to compile
stack1.c above. It is, however, suggested to use explicit command-line arguments without considering their default status when compiling your source files.
You must have already guessed that the call stack layout we saw earlier is no longer in sync with the compiled binary. We need to recreate it considering the above discussed modifications:
The default GCC command-line might have turned on other mitigation features as well. We need to investigate further before proceeding.
Tobias Klein, the author of
A Bug Hunter's Diary, maintains an awesome Bash script called
checksec.sh that provides an overview of the security features implemented within
the Linux kernel, ELF binaries and executing processes on a system. Here is a listing of its available options:
Obtain the latest version of this script (1.5 as of this writing). Let's try the --kernel option to see available mitigation features implemented within the kernel itself:

The
output above confirms that the GCC stack protector support is enabled and we have already seen it in action earlier. Let's now see what does this script has to say about the
stack1 ELF binary:
As discussed earlier, the default compilation command-line enabled quite a few mitigation features like Partial RELRO, stack canary, NX and a few others. These features have made significant modifications to the vulnerable program and their presence will prohibit its successful exploitation. From the above output, also note that the
printf and
gets functions have not been replaced with their safer counterparts. This should have happened through the default command-line. But since the program source did not include the necessary standard libraries for these functions, the
FORTIFY_SOURCE mitigation feature failed to detect their presence and as such could not replace them. If you recompile the source with the necessary libraries included, you will encounter the "
*** stack smashing detected ***" error message. Still, in the absence of this feature, the ELF binary is quite difficult to exploit.
We need to print the message to successfully exploit this program. But since the
cookie has
been reordered and placed below
buf, we simply have no way to modify it. Additionally, any attempts to overwrite the return address would fail since the canary is placed in between. While overwriting EIP, it will also be overwritten and the
__stack_chk_fail function would terminate the program before the message is printed:
In the above test run, supplying 81B of input causes the program to crash. Note the addresses of buf and cookie, 0xbf878da4 and 0xbf878da0 respectively. Variable reordering, we talked about earlier, is in effect here. We are experiencing the
influence of exploit mitigation techniques at this stage. For a successful
exploit attempt, we will have to disable these features to be able to achieve exploitation. Let's disable the stack canary mitigation feature first. Below screenshot outlines the GCC option -fno-stack-protector, that disables SSP and as such provides a wide playground for our exploit attempts. Additionally, we see how the checksec.sh script correctly identifies the absence of stack canary and fortify source mitigation features from the program:
The buf is at 0xbfbed9e4 and the cookie at 0xbfbeda34. The variables have been ordered as per our expectation. Let's have a peek at the program assembly to quickly see if the stack cookie has also been added or not:
From here we could proceed to the exploitation phase.
Solution #1:
For this solution we first need to calculate the offset between
buf and
cookie:
As expected, it came out to be 80B. We craft a perl command-line to overwrite 80B of data to reach past the buf boundary. Once this is done, we're pointing at the cookie, which can then be overwritten with the desired content:
NOTE: The test system is an x86 Intel machine that uses
little-endian byte ordering. We take this into account and reorder individual bytes to set the cookie with appropriate value.
Solution #2:
For the second solution, we need to overwrite EIP with the address of the printf statement that prints the required "you win!\n" message. This will ensure that when the program returns from main(), control transfers to stack1's .text segment again, instead of the __libc_start_main(). But first we need to find the address of the printf statement in stack1's assembly code:
The last
call instruction prepares the stack for a call to
puts. That's right, the stack is prepared for
puts and not
printf. This is due to a default
GCC optimization option that finds the second
printf call in
stack1.c incompatible with its built-in declaration and replaces (optimizes) it with a call to
puts. For our exploit attempts, we can safely ignore the implicit differences between functions used here. Since the
puts function will do the same thing as
printf, we just want its address for proper control transfer. However we need the address of the instruction just above
call puts, because it is where the "
you win!\n" message is pushed on to stack. From the above output we see that it is
0x08048479.
Now that we have the address to overwrite with, we need the exact offset where we can inject it. For this solution we need to overwrite EIP, whereas in the previous solution, we overwrote cookie, ie. 4B past buf. The size of buf was the offset that we used for junk data to reach cookie.
We concluded this offset using the variable adjacency property. All
local variables are placed adjacent to each other at lower memory
addresses in the order in which they were declared in the source
program. As such we could find out the offset of the EIP as well.
Referring the call stack layout we saw earlier, the offset of EIP can be easily calculated. The
buf 80B +
cookie 4B + saved Frame Pointer 4B = 88B. This is the offset of EIP from the start of the
buf array:
We were able to overwrite EIP and redirect control to a desired location. This action helped us to bypass the if condition without actually modifying the contents of the source program.
Solution #3:
We now move on to the third solution for this program. We have
found that the program has a buffer in which we can inject junk
data and we also have the ability to redirect control to arbitrary
locations. These two possibilities, when combined together, allow us to execute
arbitrary shellcode. We will design a shellcode that simulates the
behavior of the
puts
call and inject it within the program buffer. We will then modify the contents
of EIP to point to the buffer where our injected shellcode ends up. If
all goes well, this shellcode will be executed and we will have the
message printed.
There is however one thing we will have to think about before we move ahead. Recall the
checksec.sh output above. It tells that one of the mitigation features, NX, is enabled for the vulnerable
stack1 program. This means that when we execute this binary, it will have its stack segment marked as non-executable:
From the above output, stack is marked as
RW for the vulnerable program. As such, even if we can inject shellcode into
buf, we can not execute it. Any attempts to redirect EIP to our shellcode would be successful, however, the instant we try to execute shellcode, an exception would be raised that will eventually terminate the program. So, we'll have to disable this feature for solutions #3 and #4 to work correctly. But I'm not going to disable them for now. As you'll see, our exploit attempts would still work in the presence of NX and at the end of the post I'll point out the exact reason for such a behavior. Till then read on and try to think about why this might be happening.
First we need to design a shellcode that simulates the
puts call. I came up with the following:
The above code uses the standard Linux system calls,
write and
exit, to print the message and cleanly terminate the program. Using the
exit
call will help to remove the segmentation fault we encountered in the
previous solution, thus making our exploit much reliable. Additionally,
we use a few
shellcode writing tricks
to
remove NULL bytes from our shellcode, to reduce the shellcode size,
and to overcome the
addressing problem. Assemble and link the program to
create a standalone binary:
Here is the
objdump for the resultant
printf program:
Extract opcodes to create the required shellcode and calculate its size:
Now we are ready with the shellcode that simulates the
puts
call. Once we inject it, we would need the address of the buffer where this shellcode lands. Looking at the source and through the earlier test
executions of the
stack1 program, you already know that it prints out the address of the
buf and the
cookie variables. But we cannot just use the address from an earlier execution for our exploit. Why is this so? If you had noticed earlier, both
buf and
cookie, although adjacent and aligned as expected, had different address on each invocation:
You would have already guessed by now. It is due to the ASLR mitigation feature that is active
on the test system:
On systems that support
brk ASLR, the
randomize_va_space
file stores a value of 2. On other systems it stores a value of 1 by
default to indicate the presence of ASLR. Modifying this file with a
value of 0 will immediately turn off this feature for all newly spawned
processes:
For all the 3 invocations of
stack1 program, the locations for
buf (0xbffff4c4) and
cookie (0xbffff514) remain constant. Since the
buf is always placed at a known static address, we could use it for EIP redirection.
Let's proceed to the exploitation phase. Since the shellcode is of 38B and the
buf is located at an offset of 88B from the EIP, we have a junk space of 50B. We could use this
space to increase the reliability of our exploit by adding a NOP sled in
front of our shellcode. This although is not required as we are already
aware of the location of our shellcode.
But we still have to fill this space with junk bytes to reach the
offset of EIP. Let's craft a perl command-line to inject our shellcode at the where ths correct address could be overwritten. However,
we were not able to get the shellcode executed:
It did not work. The offset calculation was correct, address for
EIP overwrite also points to our shellcode, and we actually have a
working shellcode that, if executed, should print the winning message.
What could have gone wrong? A GDB analysis could help but this
specific issue could be debugged without using it. Have a look at the
shellcode once again:
The shellcode above is copied into the
buf array through the
gets function, which parses
newline or
EoF as input terminating characters. Unfortunately, the shellcode we so carefully
prepared contains a
newline as its last byte. This came in
through the "
you win!\n"
message and it is indeed the culprit here. The earlier exploit
command-line breaks at the
\x0a byte on offset 87, failing to overwrite
further stack locations. The EIP at offset 88 is untouched and we fail
to gain successful exploitation.
We could quickly modify the
printf.s
program and generate a new shellcode that has the message with no
newline
character. However, a quick hack can be to remove the
newline from the exploit
command-line and test it:
It did work! Although a junk byte was appended to the winning message. We are clear with the exploit technique and it is all that
matters. We used the address of
buf to jump back to our shellcode and it is one thing which makes our exploit highly unreliable. There are certain techniques through which you can reliably jump to your shellcode without using memory addresses that could possibly differ between different systems. Please refer the
Exploit writing tutorial part 2 : Stack Based Overflows – jumping to shellcode post from corelanc0d3r for more details.
For this solution, we
turned off another mitigation feature (ASLR). Even in its presence we were able to gain successful
exploitation (using solutions #1 and #2) but that was because we had alternate tricks. However, those were very specific to the vulnerable
stack1 program. They won't always work, but you now understand that an insight about how things really work, could help designing custom solutions and hacking around any limitations that stop you from gaining successful exploitation. This solution helped us to get an insight into how useful
addressing information could be for an exploit writer and how
successfully the ASLR technique helps to mitigate exploit attempts that
use this information.
Solution #4:
Let's now move to the final solution for the stack1 program. First, let's have a quick review of solution #3. We injected a shellcode that simulated the behavior of printf
statement. We redirected control to our shellcode and achieved exploitation. However, a minor modification was
required to our exploit command-line that changed the look and feel of
our winning message. The newline character caused the gets
copy loop to stop overwriting memory addresses past the terminating character and as such we
had to remove it from our exploit shellcode. Although this issue was
easily resolved though a quick and dirty hack, it might pose significant issues in
real world exploit attempts. Could there be a better/elegant solution
to this problem?
Okay, no guess work required here. There indeed is one such trick that could help us to overcome the newline issue. The shellcode we injected through the buf
array could be stored within an environment variable and then the EIP
could be overwritten with the address of this variable to get successful
execution. But wait! Where did the idea of environment variable come
from? Why are we using it anyways? How exactly does it help to bypass
the newline filter?
There
are a few scenarios in which injecting shellcode through an environment
variable is the only viable option. One such scenario is when you
encounter a buffer that is too small to fit in your desired shellcode.
Since an environment variable could be of arbitrary size, we could
inject a huge shellcode like the one simulating the
Meterpreter payload in
Metasploit Framework and get it executed on the target system. In our case, we were lucky enough to have a large
buf that could completely hold our
printf shellcode. Another scenario could be when string termination filters like the
newline above is encountered. For the solution #3, we hacked around and
got the message printed, but it obviously won't work in all cases. In
such a scenario, we could inject our shellcode into an environment
variable. Since the shellcode is injected independent of the vulnerable program, it helps to bypass its inherent filters. The only challenging part that is then left out is redirecting control to the location where this shellcode is placed.
One
of the most important reason to use an environment variable to hold
exploit shellcode is its memory placement. These variables are copied
into the stack segment of all processes and as such they provide a means
for code execution for stack-based exploits.
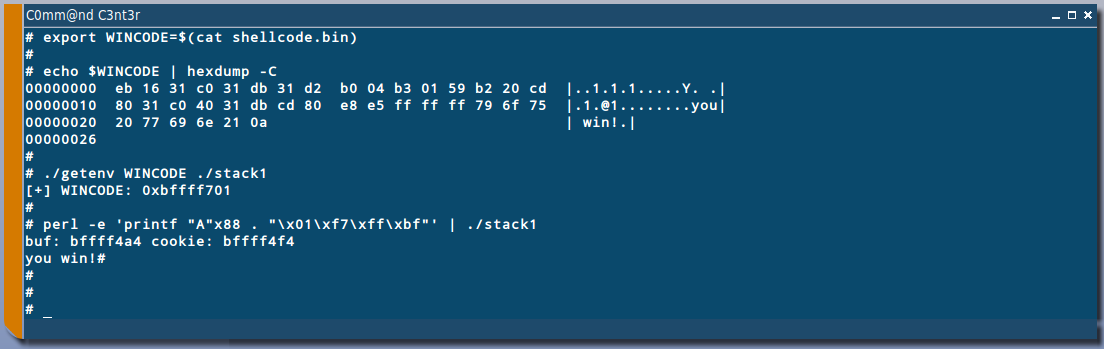
Let's inject the shellcode we prepared earlier into an environment variable, called
WINCODE and use its address to overwrite EIP and get code execution. There are a few techniques using which the address of an environment variable can accurately calculated and as such we won't need a NOP sled in front of our shellcode. If you have any queries regarding environment variables based exploitation, please refer
0x331 Using the Environment from
Hacking - The Art of Exploitation book:
We successfully redirected EIP to a NOP-less shellcode present within an environment variable. And it did work! However the output is not exactly what we had expected. There's no
newline at the end. Here is what
hexdump has to say about our exploit:
Although the environment variable has a
newline at the end, it is not echoed back when the shellcode executes. I made a small change to the original shellcode to include "
\x0a\x0d" characters and used it for testing:
This time just the "
\x0a" was echoed back and it, as expected, corrects the exploit output. However, I could not understand this strange behavior. If you have any ideas please get back.
So, we have now successfully exploited the
stack1 program through a shellcode injected into an environment variable. Please note that the use of environment variables is only possible for local exploits and as such it is not much used in common exploits that you see in the wild. However, as you have already seen, it is one of the most reliable methods of exploitation.
All these solutions are however not practical. They serve the purpose of understanding how exploits used to work before mitigation features were introduced.